
Softmax como atención lineal en prompts grandes: perspectiva basada en medidas
Descubre cómo la atención softmax se aproxima a un operador lineal con prompts grandes, facilitando el análisis teórico y la optimización en transformers.
Descubre cómo la atención softmax se aproxima a un operador lineal con prompts grandes, facilitando el análisis teórico y la optimización en transformers.

Descubre cómo ALeRCE convierte consultas en lenguaje natural a SQL para explorar bases de datos astronómicas usando modelos de lenguaje avanzados. ¡Lee más!

Descubre por qué los LLM-jueces tienen sesgos rígidos y no se adaptan a contextos cambiantes de seguridad. Un estudio revela sus limitaciones.

Descubre cómo los LLMs generan verdad fundamental sintética para clasificar emociones en audio VR. Supera limitaciones de etiquetado manual. ¡Descúbrelo!

Descubre cómo el aprendizaje en contexto (ICL) se equipara a la inferencia bayesiana. Los Transformers convergen rápidamente a la tarea real en este estudio
La arquitectura GRIL permite a redes recurrentes lineales realizar descenso de gradiente en una sola pasada, aprendiendo en contexto de forma eficiente para
Descubre cómo MapleDoctor detecta y repara errores en Text-to-SQL con ICL: 13.8% más consultas correctas, 67.4% menos latencia.
K-Prism integra conocimiento semántico, contextual e interactivo con MoE para segmentación médica. SOTA en 18 datasets. ¡Descúbrelo!

Descubre cómo los transformers profundos utilizan vectores de función para inferencia adaptativa en tareas de aprendizaje en contexto, revelando nuevos
El formato de los datos recuperados puede secuestrar la atención de los LLM, reduciendo el aprendizaje en contexto. Aprende a mitigar este efecto con estrategias efectivas.

Descubre TASM: comprime la memoria de modelos multimodales sin entrenamiento, manteniendo rendimiento y adaptabilidad. Ideal para aprendizaje en contexto.

¿Por qué el aprendizaje en contexto falla con datos estructurados? El bloqueo de prior categórico limita a los LLMs. Descubre alternativas como LoRA.
Descubre CHOP: un marco que potencia modelos ICON para generalizar a operadores fuera de distribución sin reentrenar, reduciendo errores de inferencia.

Descubre Pose-ICL, un nuevo método de IA que permite controlar la pose de objetos personalizados en generación de imágenes con alta precisión y consistencia.
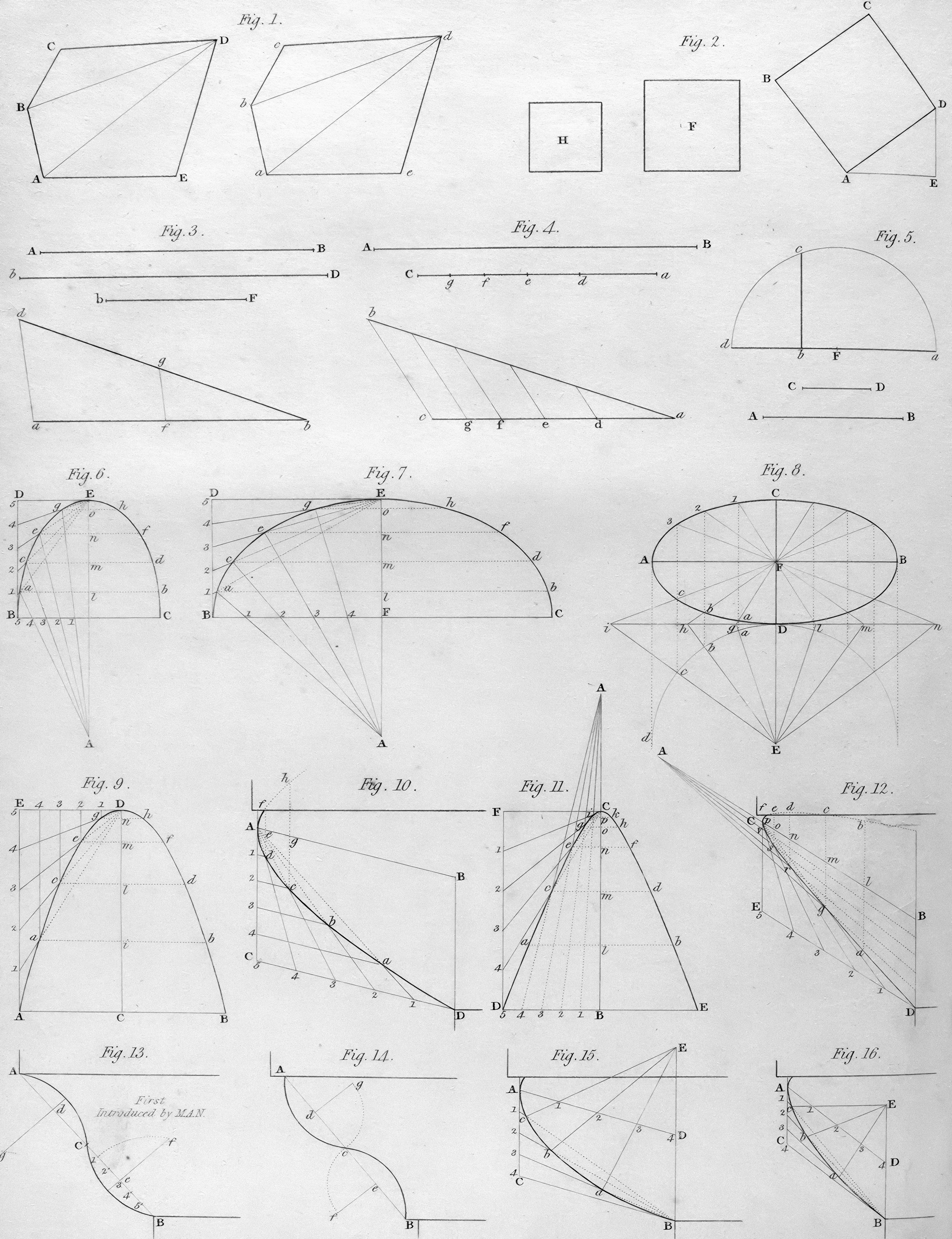
Descubre cómo los priores estructurales no paramétricos y los grafos de precedencia permiten a los LLMs predecir teoremas geométricos con un 89.29% de precisión, superando modelos supervisados.

LWM-Planner: planificación anticipada con hechos para agentes LLM. Extrae hechos de experiencias, simula el mundo y mejora decisiones sin ajustes de parámetros.

Los certificados finitos verifican la determinación contextual en LLMs y separan emergencia real de artefactos métricos. Nuevo marco teórico.

Un estudio revela que las cabezas de vector-función se dividen en escritores y canceladores, con roles opuestos en aprendizaje contextual. Conoce su impacto.
Nuevo modelo de inferencia base aprende en contexto a predecir eventos temporales sin reentrenamiento, compitiendo con modelos especializados.

Descubre cómo FIM-SDE estima con precisión funciones de deriva y difusión a partir de datos ruidosos, sin entrenamiento.